Blog
July 3, 2024

A successful Linux migration takes careful planning, preparation, and execution. This requires patience, perseverance, and a healthy dose of experience.
Although migrations from non-Linux systems like Unix or Windows do happen, the close of the CentOS Linux epoch is the compelling event driving this article. The final nail in the coffin was CentOS 7 reaching end of life on June 30, 2024. This means that CentOS Linux implementers must migrate to another OS or purchase LTS from a vendor to continue receiving updates, patches, and new features. As a result, this article is written through the lens of a forced migration off of CentOS to another comparable Enterprise Linux distribution.
In this blog, we’ll explain how to plan and execute a successful Linux migration, from assessing your current system and picking your next distro, to the steps involved in the actual migration process.
Table of Contents
Before You Migrate
There are a number of items to consider before embarking on migrating mission-critical enterprise systems from one Linux distro to another. It's one thing to migrate the operating system; it's another to port the application stack, with all its commercial and open source packages, configurations, and connections to the outside world.
It is essential to slow down and think through the process. In fact, set the stress aside and see this as an opportunity to audit your systems and implementations for areas that need improvement. Take this time to apply best practices. Fix the parts that were done wrong the first time and address items that slowly deteriorated over the years through hasty reactions to constant change.
Create Migration Roadmap
Just as I mentioned in my blog on patching CentOS and patch management best practices, the starting point is the inventory of your systems.
It is imperative to know the environment as a foundation for discovery, prioritization, and remediation. Maintain key attributes of all existing installs, including hardware details, connectivity, software versions, system class (i.e. dev/test/prod), owner point-of-contact, business purpose, etc.
If you already have this, you’re in a good position to move forward. If you don’t, then leverage this opportunity to mature your organization’s asset management process. You need this information to execute the migration, so take the time to gather and store it as a foundation for future system monitoring and maintenance.
Based on the system inventory, meet with downstream stakeholders to determine availability and note competing priorities. This will help you determine the order of system migrations and how much assistance you can expect from your colleagues. Next, conduct due diligence on vendors in the space to see what professional migration services and long-term-support (LTS) services are available.
Finally, meet with the executive team to discuss the risks, threats, and timelines, and present them with options and alternatives. Once you have an agreed upon high-level roadmap and budget, you’re ready to construct a more detailed tactical plan.
Audit Your Current Systems
With the inventory in hand, the preliminary list of prioritized systems, and a sense of your budget, the next step is to take a deeper technical dive on the target systems. Stakeholder engagement is key to the success of this phase to lay the foundation for buy-in and head off any surprises.
This is a good time to begin engagement of any external resources that were approved with the Migration Roadmap. Particularly if you want assistance in completing the system audits, as it may take a little time to get contracts in place and resources scheduled to join your team.
During this audit, you’ll look to drive out details that augment the inventory and tease out the complexity inherent in each specific system. A mature organization will have documentation on how to reproduce the current system. Ideally, there is a versioned repository of infrastructure as code with platform engineering details in place to replicate and tune the new environment. If available, that information will expedite the audit process and help lay the foundation for a rollout plan and a communication plan.
In either case, dig in and account for these key factors:
- Determine downtime tolerance and/or a cut-over strategy
- Identify and/or develop the regression test procedures for validating migration success
- Solidify subject matter expert involvement, including:
- Sign-off on the rollout plan, including potential rollback details
- Availability to assist with the migration and/or rollback
- Validation and sign-off on the migration and/or rollback
- Document how to backup all important data and configs prior the migration
- Identify application dependencies that must also be migrated*
- Identify system and application configuration files that need to be migrated
- Document any changes that will be required to system and application configurations
- Acknowledge existing system issues and agree on a remediation or deferral plan, including:
- Performance, availability, stability, or maintenance problems
- Organizational policy compliance problems
- Deviations from industry best practices
- Locate any "band-aids" that have been applied and make adjustments to eliminate them
- Review existing documentation and markup changes to reflect the state of the future system
Always plan for the worst and hope for the best. Be sure to have a Disaster Recovery (DR) plan in place. Sometimes you can't roll back and need to restore from scratch. The duration of the DR measures should be taken into account when considering downtime.
*Note: Knowing the application dependencies will be essential for choosing a new distro. Some varieties have a broader ecosystem of support than others. Your application may need a popular distribution or some extra care and feeding during the install.
Need Help With Your Linux Migration?
OpenLogic can assist with planning your Linux migration or perform the migration itself. Click the button below to learn about our professional migration services.
Choose Your Next Linux Distro
There are a number of factors that come into play when chasing down and settling on a particular Linux distribution to fit all the needs of your system or broader organization. You should always start by ensuring that you have hardware and software compatibility, then begin to assess other factors. Make sure there is quality documentation and training available for your team to reference as system needs evolve or when problems arise. Don’t forget to look into the purveyor of the distro to determine whether their background, values, and approach fit the culture of your organization.
There are countless alternatives. To get some background and expedite your research, take a look at our previous blog on Finding the Best Linux Distro. Through the lens of a forced migration off of CentOS, you can likely concentrate on the “Fedora and RHEL-based Enterprise Linux Distros” section in that article. This will get you to the short-list of preferred paths that avoid all the most common pitfalls of interoperability with existing foundational services. That section lists distributions that focus on stability, reliability, and long-term support for server-based applications.
At OpenLogic, we focus on open source distributions. To us, it is essential to consider the strength of the community, and our standby metric for this is adoption rate.
As I wrote in my blog on lightweight Linux distros, “Make sure the distro is going to continue to evolve and meet future needs. Take a look at key attributes like frequency of releases and availability of support, as well as the quality and accessibility of documentation for installation, configuration, and troubleshooting. A fairly good measure of all these things can be assumed by the strength of adoption, so look for distributions that have a large user base.”
See the chart below for adoption rate by OS. No metric is perfect, but this one is pretty good. It shows the trend of unique systems, by OS, that hit the Extra Packages for Enterprise Linux (EPEL) each week. This data shows the steady growth in adoption for both AlmaLinux and Rocky Linux. This is certainly due in large part CentOS migrations to these distros. Interestingly, RHEL and CentOS Stream have remained fairly flat or had more moderate growth during this same time period.
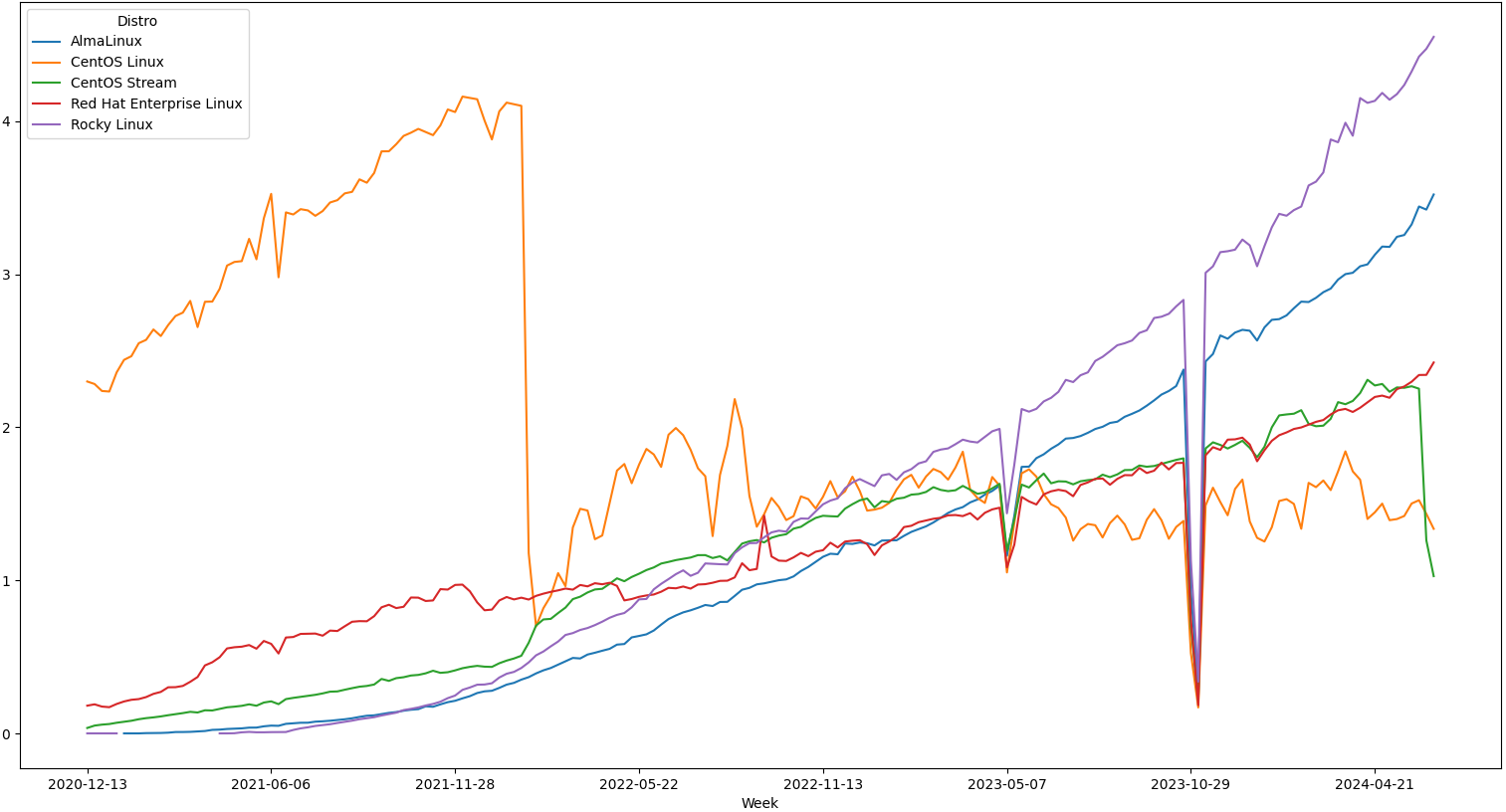
Most OpenLogic customers have chosen to adopt either Rocky Linux or AlmaLinux. They both have a healthy community and large user base. However, their approach to producing the distribution is slightly different.
- Rocky Linux strives for bug-for-bug compatibility with RHEL, by creating a distribution using the RHEL source code. Rocky Linux most closely follows the approach of the now end-of-life CentOS Project.
- AlmaLinux promises behavioral compatibility with RHEL, by creating a distribution using a curated list of packages from the CentOS Stream project that matches those found in the RHEL distribution.
Both of these approaches rely on contributions to CentOS Stream for long-term support. Although the timelines for releases of new features and patches will tend to leapfrog one another.
Linux Migration: Step-by-Step Guide
When conducting the migration, there are essentially four overarching phases that will occur. You’ll install the new operating system on the target machine. You will configure and tune the machine to support the application it is hosting. You will run a predetermined set of tests to validate the system and its applications are operating as expected. Then, you’ll take steps to move the execution of all production workloads from the old system to the new one.
In dealing with a one-off single server system, you can get away with conducting these steps manually. With careful planning, a cautious and meticulous person can even do this for a handful of integrated machines. However, manual installations do not scale. It quickly becomes necessary to apply automation of some kind in order to conduct all the steps in a quick and repeatable way.
For large enterprises, it is critical to use some combination of tools like Puppet, Terraform, Ansible, and others to enable version controlled tasks that are automated, repeatable, and self-reporting. Otherwise, human error is inevitable and implementation timelines will be unacceptable.
The following table highlights the activities, milestones, and considerations for each of the four phases, and it showcases the difference between a manual vs. automated approach. More complex environments will certainly require more elaborate set of commands for vetting and validating the new system.
| Manual | Automated | |
|---|---|---|
| Installation |
|
|
| Configuration** |
|
|
| Validation |
|
|
| Transition |
|
|
**Note: During the configuration steps, don’t forget to take advantage of the opportunity to start fresh by applying best practices that may have been ignored before. For example:
- Disable root login
- Minimize user accounts
- Apply principle of least privilege
- Eliminate password access and require SSH keys
- Remove unused services and add restrictive firewall rules to reduce the attack surface
- Implement a default deny access policy
Final Thoughts
Remember, DON’T RUSH! Consider using a vendor like OpenLogic for LTS patching to extend your runway and/or provide migration services to augment your staff. Getting external assistance can help your organization mitigate the platform compliance risk while maintaining forward momentum on business-critical projects.
A healthy community is a key success factor in choosing your distribution. However, commercial support is still a viable option in this space, and it can be beneficial to have a trusted partner like OpenLogic to help you solve sticky problems fast, often times in conjunction with the community.
This Blog Was Written By One of Our Linux Experts.
OpenLogic Linux experts have at least 15 years of experience managing complex enterprise deployments. They can evaluate your environment and make unbiased recommendations to guide your Linux migration. Click the button below to get started.
Additional Resources
- Blog - Applying CIS Benchmarks to Your Linux OS With Hardened Images
- Blog - Setting a CentOS Migration Strategy
- Blog - Best Practices for Keeping Your Linux Server Secure
- Guide - Navigating CentOS End of Life
- White Paper - Decision Maker's Guide to Enterprise Linux
- Datasheet - Enterprise Linux Support and Services
- Blog - Top Enterprise Linux Distributions (State of Open Source Report)
- Video - CentOS 7 Migration Recommendations